Striving for Simple vs. Easy
Rich Hickey’s Simple Made Easy is one of the most influential tech talks I’ve watched. This talk is responsible for my remarkably slower development these days. I spend the majority of the time distilling the problem, and then implementing a better solution faster.
Interalizing the lesson isn’t easy, though. I’d like to share an example I worked through recently, these things are often obvious in retrospect.
Spark
Apache Spark has been great for our workloads. It provides an easy way for us to manipulate data from disparate sources in a consistent way. With PySpark, we can write Python scripts that pull data from PostgreSQL, CSV’s, ORC files, manipulate it, and spit it back out to any of those sources.
I built a workflow (literally Step Function) for executing Spark scripts. The workflow will:
- Stand up a Spark cluster based on sizing argument
- Execute provided scripts when the cluster is ready
- Tear down the Spark cluster when complete
- Pass/fail the workflow based on output verification
The workflow is great. It has been built simple and sturdy. There are alarms in place for clusters idling too long, or simply being up too long.
The Problem
Spark is good at reading data from PostgreSQL, but it needs connection information like credentials to do this. The connection information lives in our secrets management tool. In addition, many scripts are actually templates, needing arguments to fill in specific values.
A Solution
The Spark workflow uses containers to submit scripts. This encapsulates the lifecycle of a Spark job/script, makes logging easy to find and follow, and is lightweight.
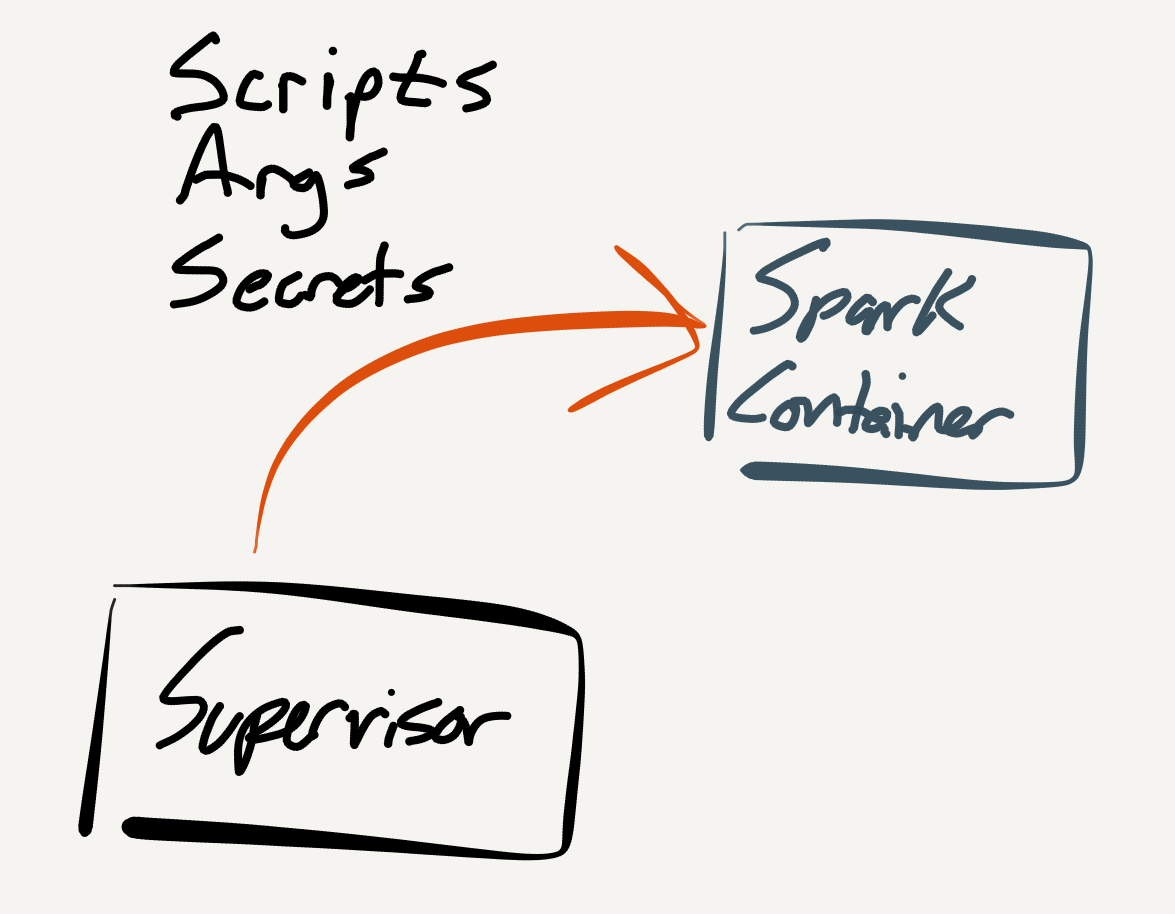
My first approach was easy. The submit container pulls arguments and secrets together and formats the template prior to Spark submission. It looked a little like this (please excuse potato quality drawings):
Complect
This Rich-ism is a perfect label for a common problem in tech. It means intertwining concerns and responsibilities. In this case, we have complected executing Spark scripts and assembling those scripts.
That realization led to simplification.
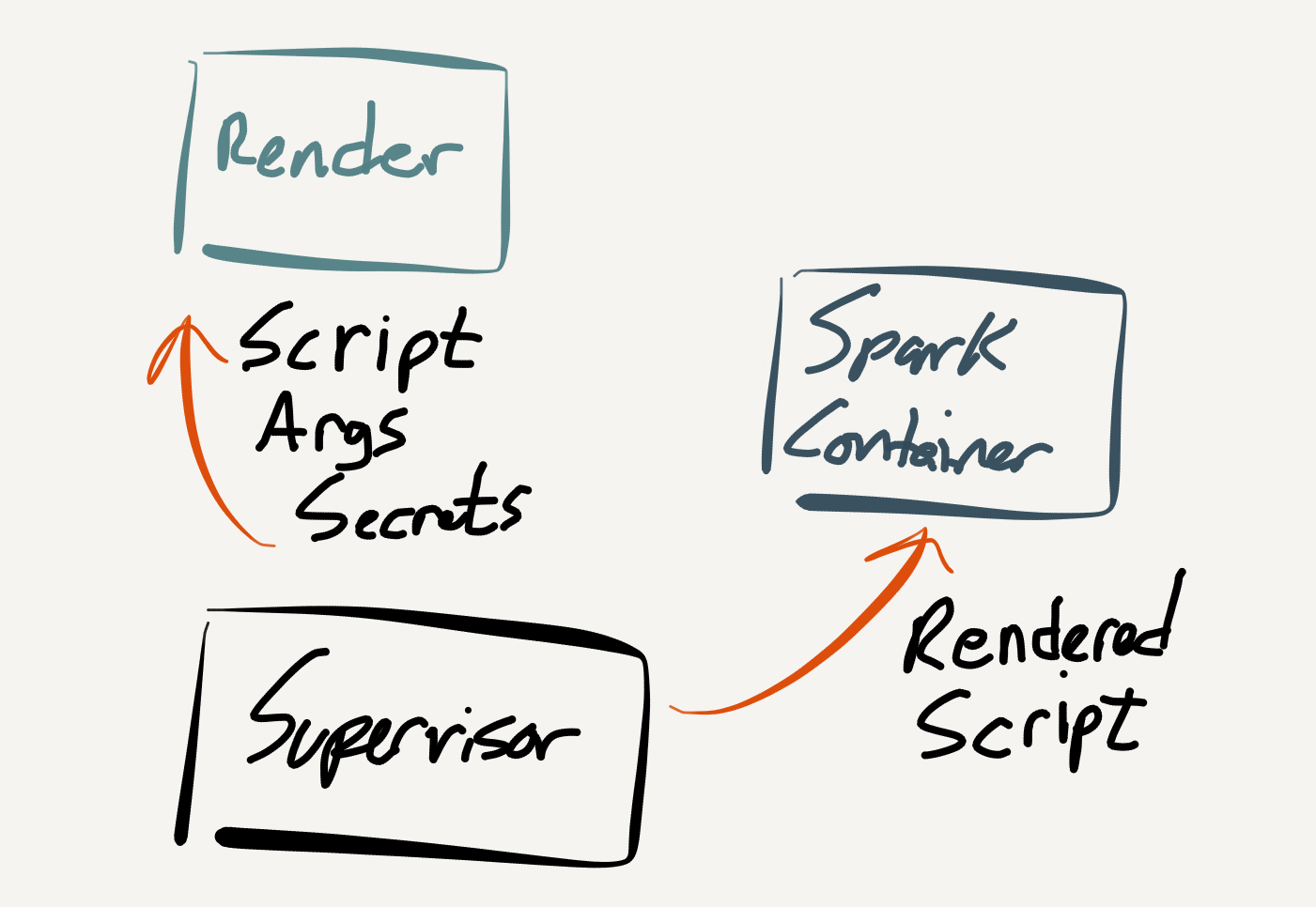
A Better Solution
The simple solution was to introduce a rendering service for marrying parameters, secrets, and script templates. Not only does this solve our problem, it also makes our secret fetching well encapsulated and extensible.
The Spark workflow is left to a single responsibility of executing a script, with no other concerns. The solution looks like this: